优先级队列
在很多具体的应用条件下,我们都只关心一组数据中的最大值或者最小值,比如考完试大家首先都是看谁是第一名,谁又是最后一名;比如我只知道世界最高峰是珠穆朗玛峰,却不知道后面的第二第三都是什么;比如在操作系统中的诸多算法,都是基于优先级来进行的,像是页面置换算法还有进程调度算法,这个时候总是选出其中优先级最高的页面将它换出,或者优先级最高的进程,让它占用CPU。
支持上面这种操作,即每次只是获得其中取到最值的元素,的抽象数据类型,就是我们这里要讲的优先级队列(Priority Queue)。除了获得其中的最值元素外,优先级队列显然还应该支持元素的动态插入与删除,以及判空操作与获得元素的个数。据此,可以给出优先级队列的抽象类:
template <typename K, typename V>
class PriorityQueue{
public:
virtual int size() = 0;
virtual bool empty() = 0;
virtual V* getMax() = 0;
virtual void insert(K key, V value) = 0;
virtual void delMax() = 0;
}
优先级队列的实现
可以有很多方法来实现上面定义的优先级队列ADT。例如我可以直接用一个最简单的向量Vector作为优先级队列的底层结构。调用getMax时,就对向量中的所有元素一一遍历,并返回其中的最大值。同理,调用delMax时,首先调用getMax找到这个最大元素,并且将它从向量中移除。很明显,这两个操作的时间复杂度都是O(n)。
我们不难找到一种更加高效的底层结构,比如在前面说过的多种平衡二叉搜索树,比如AVL树或者红黑树。根据前面的知识,无论是插入元素还是删除最大值元素,都只需要O(logn)的时间;而为了实现getMax操作,只需沿二叉树的最右侧路径不断深入,直到最后一个结点,它的时间复杂度正比与二叉树的高度,即也是O(logn)。
利用平衡搜索树的确可以做到非常高效地实现优先级队列。让我们进一步考察平衡搜索树,在平衡搜索树中,本质上维护了所有元素的一个全序关系,实际上,搜索树的中序遍历正是对应了所有元素的一个有序序列。但是应该注意到,优先级队列并不需要一个这么强的条件,它只是要求每次访问到最大元素就可以了,并不关心最大元素外的其他元素是否是按序排列的。因此,BBST的功能实际上远远超出了优先级队列的要求,而为了维护这些额外的信息也是需要成本的。
因此,或许有更为简单的底层结构,它的维护更为简单,因此上面几个基本操作的成本也要更优于BBST,至少在常系数的意义下。而这就是我们要详细叙述的平衡二叉堆和左式堆,其中左式堆在左式堆(leftist heap)中做了说明。
堆>完全二叉堆的基本概念
结构性不言而喻,堆>完全二叉堆在结构上是一棵完全二叉树。如下图所示:

这意味着,可以简明地利用向量Vector来作为它的底层结构,因为此时父子结点之间的链接关系,可以直接通过它们的秩Rank来体现,而不需要像一般的树结构那样显式地给出链接。具体说来,假设根节点从0开始编号,则对于任意秩为i的节点,它的父节点的秩一定为(i - 1) / 2,它的左孩子的秩一定为2i + 1,右孩子的秩一定为2i + 2(如果左右孩子存在的话)。因此,可以给出下面的宏定义:
#define PARENT(i) ((i - 1) >> 1)
#define LEFTCHILD(i) ((i << 1) + 1)
#define RIGHTCHILD(i) ((i << 1) + 2)
而堆序性则是指堆>完全二叉堆维护的内部元素的偏序关系,具体说来就是任意节点的值(或者优先级)不小于它的两个孩子节点。即
CBHeap[i] >= MAX(CBHEAP[LEFTCHILD(i)], CBHEAP[RIGHTCHILD[i]]);
很明显,堆序性是相比于二叉搜索树的有序性弱得多的条件。在堆序性的前提下,只能保证沿任意一条路径,元素的值是自上而下递减的,而在堆>完全二叉堆的左右子树之间,没有任何的大小关系。但是通过堆序性我们可以得到,堆>完全二叉堆的堆顶CBHEAP[0]是全局的最大元素,这样,只要直接取出堆顶,就可以实现了getMax函数:
template <typename K, typename V>
V* CBHeap<K, V>::getMax(){
if(empty()) return nullptr;
return _elem[0];
}
下面重点阐述如何基于堆>完全二叉堆实现优先级队列ADT,即实现其中的insert和delMax函数。实际上,任何数据结构的实现,都必然在于两个方面,即首先利用它的某些内部性质完成相应的功能,比如插入与删除,然后通过有限的调整保证操作之后这些性质仍然是满足的。前面的AVL树是如此,伸展树是如此,B树和红黑树都是如此,这里的堆>完全二叉堆也是如此。
堆>完全二叉堆的实现
插入接口的实现
由于堆>完全二叉堆的底层是采用向量Vector来实现的,为了将一个新的元素插入到向量中,最简明最高效的策略是直接将这个元素放到向量的末尾,这个操作只需要O(1)的时间。但是这样操作以后,堆的堆序性很可能遭到破坏,因此下面主要讨论如何恢复堆序性。
应该注意到,将一个元素插入到向量的末尾后,只有可能在新插入的元素及它的父亲节点之间不满足堆序性,而不会影响到所有其他元素,这是因为前面讲到的,堆的左右子树之间不存在任何的次序关系。
如果新插入的元素和它的父节点之间的确不满足堆序性,即新插入的元素大于它的父亲节点,为了恢复堆序性,只需要将这两个元素交换即可。这样一次操作之后,虽然原有的堆序性得到满足,但是新插入的元素又有可能与它的新的父亲节点之间不满足堆序性。为此,我们只需要不断地重复交换操作,直到这种冲突不再发生。插入的过程如下图所示:

可以看到,在这种插入策略下,新插入的节点是由下而上不断攀升的,因此这种插入又被称为上滤插入。为了实现上滤插入,可以首先将上滤操作进行抽象,形成一个内部函数,在insert中调用该函数即可。具体的代码如下:
template <typename K, typename V>
void CBHeap<K, V>::percolate_up(int pos){
entry<K, V> tmp = get(pos);
while(HASPARENT(pos)){
if(get(PARENT(pos)) >= tmp) break;
get(pos) = get(PARENT(pos));
pos = PARENT(pos);
}
get(pos) = tmp;
}
template <typename K, typename V>
void CBHeap<K, V>::insert(entry<K, V> e){
push_back(e);
percolate_up(getSize() - 1);
}
容易证明,这种插入策略是正确的,因为每次交换都可以解决原有的堆序性冲突。虽然这种冲突可能在插入结点与新的父亲节点之间再次出现,但是此时插入结点的高度已经提升了一个单位,并且至多提升到树根,因此至多进行h次交换操作,这里的h为完全二叉树的高度。
在这里,已经可以看出堆>完全二叉堆相对于BBST的优势了——对于BBST而言,虽然插入操作也只需要O(logn)的时间,但是正如我们前面也提到过的,平衡二叉树的平衡并非一种绝对平衡,而是相对的平衡,它的树高只是在渐进意义上可以达到O(logn),却往往具有一个比较大的常系数。而对于堆>完全二叉堆而言,它的树高就是严格的logn,因此在常系数的意义下是优于BBST的。
删除接口的实现
为了删除堆中的最大元素,只需要将向量的首元素摘除就可以了,但是接下来的问题是,如何在摘除首元素后保证堆序性,即找到一个新的最大元素作为首元素。
首先,为了摘除首元素,是不可能调用向量的pop_front接口的,因为这将涉及到剩下n - 1个元素的整体移动,时间复杂度为O(n)。为此,只需要仿照插入时的策略,将向量中的最后一个元素last_elem填补到首元素,这样就保证了堆的结构性,以及除了新的树根与它的两个孩子节点以外的堆序性。
为了修复树根处的堆序性,可以将last_elem与它的两个孩子节点进行比较,并且将其中的最大者(堪为父者)作为新的树根,此时树根处的堆序性将得到修复。但是和插入节点的情形一样,此时堆序性冲突有可能传递到last_elem的新位置处,此时只需要简明地重复上面的操作,直到这种堆序性冲突不再发生。删除最大元素的过程如下图:
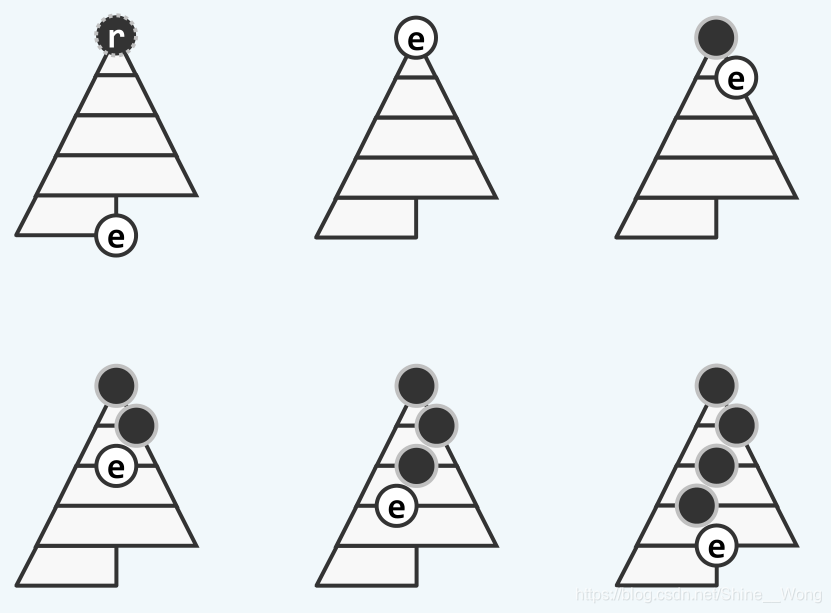
可以看到,为了调整堆的堆序性,被放置到树根的末元素是由上至下不断下降的,因此这种删除策略也被称为下滤删除。我们同样可以将下滤操作进行抽象,然后在delMax函数中调用下滤操作来实现delMax函数。具体的代码如下:
template <typename K, typename V>
int CBHeap<K, V>::proper_parent(int pos){
if (!HASLCHILD(pos)) return pos;
if (!HASRCHILD(pos)) return get(pos) >= get(LCHILD(pos)) ? pos : LCHILD(pos);
int proper = get(pos) >= get(LCHILD(pos)) ? pos : LCHILD(pos);
return get(proper) >= get(RCHILD(pos)) ? proper : RCHILD(pos);
}
template <typename K, typename V>
void CBHeap<K, V>::percolate_down(int pos){
entry<K, V> tmp = get(pos);
for(int p = proper_parent(pos); p != pos; p = proper_parent(pos)){
get(pos) = get(p);
pos = p;
get(pos) = tmp;
}
}
template <typename K, typename V>
entry<K, V> CBHeap<K, V>::delMax(){
entry<K, V> max = get(0);
_elem[0] = _elem[_size-- - 1];
percolate_down(0);
return max;
}
和上滤插入一样,容易证明下滤删除策略的正确性,因为这种下滤至多只会进行h次,h是完全二叉树的树高。因此,删除最大结点的时间复杂度仍然是O(logn)。
批量建堆
很多具体的应用场景中,初始的输入都是成批给出的,此时需要考虑的一个问题是,如何高效地将这些初始的数据组织成一个堆>完全二叉堆,也就是这里的批量建堆问题。
蛮力算法
实际上,这个问题可以借助上面已经实现的insert接口快速地解决。为了将n个初始给定的元素组织成一个堆>完全二叉堆,只需要对这n个元素依次调用insert函数即可,于是形成了下面的代码:
template <typename K, typename V>
void CBHeap<K, V>::heapify(entry<K, V>* elems, int n){
for(int idx = 0; idx != n; ++idx)
insert(elems[idx]);
}
这种实现方法虽然简单,性能却比较糟糕。根据上面的分析,每次调用insert函数的时间复杂度为O(logn),这样,将n个元素组织成一个堆>完全二叉堆需要的时间成本为O(nlogn),而在相同的时间内,已经可以对这n个元素做一个全排序了,我们这里却只得到了一个偏序关系,可见,这里的批量建堆算法是还有提升的余地的。
进一步考察这里的蛮力算法,可以看到,将所有的输入元素都组织成一个向量之后,第一次将一个元素插入到空堆当中,即形成了一个规模为1的堆;接下来插入第二个元素,等价于对向量中的第二个元素进行一次上滤操作percolate_up,于是形成了一个规模为2的堆;以下同理,再对接下来的元素进行上滤,形成一个规模为3的堆。
因此,这里的蛮力算法,其实是等价于将向量中的每一个元素,依次调用一次上滤操作percolate_up,就可以使之成为一个堆>完全二叉堆。每个元素上滤的成本正比于它的深度,设最终堆>完全二叉堆的高度为h,所以蛮力算法的时间复杂度为
2 × 1 + 2 2 × 2 + ⋯ + 2 k × k + ⋯ + 2 h × h = ( h − 1 ) × 2 h + 1 + 2 = O ( n l o g n ) 2\times 1 + 2^2\times 2 + \cdots + 2^k\times k + \cdots + 2^h \times h = (h - 1)\times 2^{h + 1} + 2 = O(nlogn) 2×1+22×2+⋯+2k×k+⋯+2h×h=(h−1)×2h+1+2=O(nlogn)
与上面分析的结论一致。
Floyd算法
首先来考虑一个问题,对于两个给定的堆,和任意一个独立的节点,如何将它们组织成一个更大的堆。
实际上,这个问题已经在前面有过讨论了——在删除最大节点的算法中,不正是将向量末尾的节点作为新的树根,然后将该节点与左右子树两个堆进行合并吗?因此,只需要将两个给定的堆分别作为独立节点的左子树与右子树,然后对独立节点调用一次下滤操作percolate_down就可以了。
我们可以将上面的讨论推广到批量建堆的算法当中。首先需要明确,单个节点本身也形成一个堆>完全二叉堆,满足结构性与堆序性。为了将所有的输入元素组织成一个堆>完全二叉堆,首先仍然将它们组织成在一个向量当中,并且将它视作一棵完全二叉树,在初始状况下,只有树的所有叶节点各自构成一个规模为1的堆>完全二叉堆。为了将这些堆>完全二叉堆合并成一个更大的堆>完全二叉堆,首先对于完全二叉树中的最后一个内部节点调用上面的合并算法,此时该节点连通它的孩子节点将构成一个更大的堆,此后只需要自后向前不断重复上述过程,就可以将各个子堆逐层合并,最终堆序性将在全局得到恢复。这就是Floyd建堆算法,它的代码如下:
#define LASTINTERNAL(n) PARENT(n - 1)
template <typename K, typename V>
void CBHeap<K, V> heapify(entry<K, V>* elems, int n){
copyfrom(elems, 0, n);
for(int idx = LASTINTERNAL(n); idx >= 0; --idx)
percolate_down(idx);
}
对Floyd算法进行分析,每一个内部节点,都将调用一次percolate_down函数,它的成本正比于每个节点的高度,因此整体的时间复杂度应该取决于所有内部节点的高度总和。假设完全二叉树的高度为h,则Floyd算法的时间复杂度为:
h × 1 + ( h − 1 ) × 2 + ⋯ + ( h − k ) × 2 k + ⋯ + 1 × 2 h − 1 = 2 h + 1 − h − 2 = n − l o g ( n ) = O ( n ) h \times 1 + (h - 1)\times 2 + \cdots + (h - k)\times 2^{k} + \cdots + 1 \times 2^{h-1} = 2^{h + 1} - h - 2 = n - log(n) = O(n) h×1+(h−1)×2+⋯+(h−k)×2k+⋯+1×2h−1=2h+1−h−2=n−log(n)=O(n)
可以看到,Floyd算法和蛮力算法相比,蛮力算法是每个节点都调用一次上滤操作percolate_up,而Floyd算法是每个节点调用一次下滤操作percolate_down,而这就导致了它们性能上的巨大差别。具体说来,上滤操作的时间复杂度正比于节点的深度,而下滤操作的时间复杂度正比于节点的高度,对于堆>完全二叉堆中的所有节点,大部分都是处于底层的节点,它们的高度较小而深度较大,因此Floyd算法就是让多数节点的操作较快,而蛮力算法则是使多数节点的操作更慢,这就是它们性能上差别的本质原因。实际上,Floyd算法就类似于Huffman树的思想——使处于底层的多数节点具有更小的权重,或者更快的操作。
堆排序
堆的一个具体的应用就是堆排序算法。它的本质其实就是选择排序SelectSort,只是在选择当前最大元素的过程中,调用了堆的getMax函数,使得一次选择的时间消耗减少了。因为太简单,这里就不多叙述了。